Фінансові новини
- |
- 17.07.26
- |
- 02:42
- |
-
 RSS
RSS - |
- мапа сайту
Авторизация
|
| |
|
"Не на користь книжку читать, коли вершки лише хапать" Українське прислів'я |
Математики розробили складні задачі для перевірки міркування Gemini, Claude та GPT-4o — вони провалили майже всі тести
09:58 21.11.2024 |

Найсучасніші моделі штучного інтелекту розв'язали лише 2% складних математичних задач, розроблених провідними математиками світу.
Дослідницький інститут Epoch AI представив новий набір тестів FrontierMath, який потребує докторського рівня математичних знань. До розробки залучили професорів математики, зокрема лауреатів Філдсівської премії. На розв'язання таких задач у математиків-докторів може йти від кількох годин до днів.
Якщо у попередніх тестах MMLU моделі ШІ успішно розв'язували 98% математичних задач шкільного та університетського рівня, то з новими завданнями ситуація кардинально інша.
«Ці завдання надзвичайно складні. Наразі їх можна розв'язати лише за участю фахівця у цій галузі або за допомогою аспіранта у суміжній сфері у поєднанні з сучасним ШІ та іншими алгебраїчними інструментами», - зазначив лауреат Філдсівської премії 2006 року Теренс Тао.
У дослідженні протестували шість провідних моделей ШІ. Gemini 1.5 Pro (002) від Google та Claude 3.5 Sonnet від Anthropic показали найкращий результат - 2% правильних відповідей. Моделі o1-preview, o1-mini та GPT-4o від OpenAI впоралися з 1% завдань, а Grok-2 Beta від xAI не змогла розв'язати жодної задачі.
FrontierMath охоплює різні математичні галузі - від теорії чисел до алгебраїчної геометрії. Усі тестові завдання доступні на вебсайті Epoch AI. Розробники створили унікальні задачі, яких немає у навчальних даних моделей ШІ.
Дослідники зазначають, що навіть коли модель надавала правильну відповідь, це не завжди свідчило про правильність міркувань - іноді результат можна було отримати через прості симуляції без глибокого математичного розуміння.
ТЕГИ
 Від закликів до партнерів "Закрийте небо над Україною!" до заяви
українського президента Володимира Зеленського: "Freyja - це спосіб
доповнити нашу оборону, створити надійний щит над усією Європою"
минуло чотири з половиною роки.
Від закликів до партнерів "Закрийте небо над Україною!" до заяви
українського президента Володимира Зеленського: "Freyja - це спосіб
доповнити нашу оборону, створити надійний щит над усією Європою"
минуло чотири з половиною роки. ТОП-НОВИНИ
 Україна першою отримає нові французько-італійські системи SAMP/T NG для протидії балістичним ракетам.
Україна першою отримає нові французько-італійські системи SAMP/T NG для протидії балістичним ракетам.  Верховна Рада проголосувала за звільнення Юлії Свириденко з посади
прем'єр-міністерки України, що означає відставку всього складу Кабінету
міністрів.
Верховна Рада проголосувала за звільнення Юлії Свириденко з посади
прем'єр-міністерки України, що означає відставку всього складу Кабінету
міністрів. Верховна Рада підтримала в першому читанні законопроєкт №15294 про
посилення відповідальності за виготовлення і розповсюдження дитячої
порнографії, що також містить положення про декриміналізацію дорослого
контенту.
Верховна Рада підтримала в першому читанні законопроєкт №15294 про
посилення відповідальності за виготовлення і розповсюдження дитячої
порнографії, що також містить положення про декриміналізацію дорослого
контенту. На Міжурядовій конференції Україна-ЄС офіційно
відкрили Кластер 6 у переговорах про вступ України до ЄС, під назвою
«Зовнішні відносини».
На Міжурядовій конференції Україна-ЄС офіційно
відкрили Кластер 6 у переговорах про вступ України до ЄС, під назвою
«Зовнішні відносини».ПІДПИСКА НА НОВИНИ
ПРЕС-РЕЛІЗИ
 Ця тилова вакансія підходить для кандидатів, що не можуть
виконувати бойові завдання у звʼязку із віком чи станом здоровʼя.
Ця тилова вакансія підходить для кандидатів, що не можуть
виконувати бойові завдання у звʼязку із віком чи станом здоровʼя.  Страхова компанія VUSO (ВУСО) за
підсумками 2025 року сплатила понад 348 мільйонів гривень податків до
бюджетів усіх рівнів. Водночас загальний обсяг допомоги компанії Силам
оборони України з початку повномасштабної війни наближається до 100
мільйонів гривень.
Страхова компанія VUSO (ВУСО) за
підсумками 2025 року сплатила понад 348 мільйонів гривень податків до
бюджетів усіх рівнів. Водночас загальний обсяг допомоги компанії Силам
оборони України з початку повномасштабної війни наближається до 100
мільйонів гривень. У РУБРИЦІ
 Від кінця 2022 року, коли компанія OpenAI публічно представила
ChatGPT - перший масовий чат-бот штучного інтелекту (ШІ), минуло зовсім
небагато часу за мірками людства і ціла вічність для технологій.
Від кінця 2022 року, коли компанія OpenAI публічно представила
ChatGPT - перший масовий чат-бот штучного інтелекту (ШІ), минуло зовсім
небагато часу за мірками людства і ціла вічність для технологій.
 Європейський Союз (ЄС) запровадить вікові обмеження для неповнолітніх
користувачів соціальних мереж. Про це в понеділок, 13 липня, заявила
голова Єврокомісії (ЄК) Урсула фон дер Ляєн
Європейський Союз (ЄС) запровадить вікові обмеження для неповнолітніх
користувачів соціальних мереж. Про це в понеділок, 13 липня, заявила
голова Єврокомісії (ЄК) Урсула фон дер Ляєн  Флагман OPPO Find X10 Pro Max, котрий вийде восени, вперше в історії
смартфонів отримає три камери по 200 МП, повідомляє інсайдер Digital
Chat Station. Ще 50 МП приходиться на фронтальну камеру.
Флагман OPPO Find X10 Pro Max, котрий вийде восени, вперше в історії
смартфонів отримає три камери по 200 МП, повідомляє інсайдер Digital
Chat Station. Ще 50 МП приходиться на фронтальну камеру. Глобальні реєстрації електромобілів і plug-in гібридів у червні зросли на 7% у річному вимірі - до 2 млн одиниць.
Глобальні реєстрації електромобілів і plug-in гібридів у червні зросли на 7% у річному вимірі - до 2 млн одиниць.  Угода про виробництво чипів між Apple та Intel могла бути підписана під
тиском, оскільки адміністрація Білого дому планувала запровадити
100-відсоткові мита на кремній, який використовується в iPhone та Mac.
Угода про виробництво чипів між Apple та Intel могла бути підписана під
тиском, оскільки адміністрація Білого дому планувала запровадити
100-відсоткові мита на кремній, який використовується в iPhone та Mac.  Компанія Radia розширила команду інженерів, що працюють над своїм
вантажним літаком WindRunner, обравши аерокосмічні компанії Latecoere та
Stirling Dynamics для розробки двох найважливіших систем літака.
Компанія Radia розширила команду інженерів, що працюють над своїм
вантажним літаком WindRunner, обравши аерокосмічні компанії Latecoere та
Stirling Dynamics для розробки двох найважливіших систем літака.
 OpenAI офіційно представила ChatGPT Work - новий інструмент, який
об'єднує можливості чат-бота, агента для виконання завдань і
програмування в одному застосунку.
OpenAI офіційно представила ChatGPT Work - новий інструмент, який
об'єднує можливості чат-бота, агента для виконання завдань і
програмування в одному застосунку. BIN™ не завжди поділяє думку авторів публікацій
Любе використання інформації агентств "Українські Новини" та "інтерфакс-Україна" ЗАБОРОНЕНО!
 Google
оголосила про запуск нової функції Video Remix для сервісу Google
Photos. Вона дає змогу редагувати та стилізувати вже збережені відео за
допомогою штучного інтелекту Gemini Omni, який виконує зміни на основі
текстових підказок користувача.
Google
оголосила про запуск нової функції Video Remix для сервісу Google
Photos. Вона дає змогу редагувати та стилізувати вже збережені відео за
допомогою штучного інтелекту Gemini Omni, який виконує зміни на основі
текстових підказок користувача. Samsung оголосила про початок серійного виробництва SSD PM1763 PCIe 6.0, призначеного для серверів наступного покоління.
Samsung оголосила про початок серійного виробництва SSD PM1763 PCIe 6.0, призначеного для серверів наступного покоління. Компанія Meta анонсувала модель штучного інтелекту Muse Image для
генерації та редагування зображень. Це перша розробка підрозділу Meta
Superintelligence Labs у цьому напрямі.
Компанія Meta анонсувала модель штучного інтелекту Muse Image для
генерації та редагування зображень. Це перша розробка підрозділу Meta
Superintelligence Labs у цьому напрямі.  Google
почав використовувати завантажені у пошук фото, аудіо й відео для
навчання своїх ШІ-моделей, і опція увімкнена в усіх за замовчуванням.
Google
почав використовувати завантажені у пошук фото, аудіо й відео для
навчання своїх ШІ-моделей, і опція увімкнена в усіх за замовчуванням.
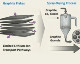 Південнокорейські дослідники розробили нову технологію виробництва
сухих електродів з гранул графіту з контрольованою формою для анодів акумуляторів електрокарів.
Південнокорейські дослідники розробили нову технологію виробництва
сухих електродів з гранул графіту з контрольованою формою для анодів акумуляторів електрокарів. Із 7 липня Google змінює правила підрахунку використаного сховища для
облікових записів. Відтепер усі дані резервних копій Android
зараховуватимуться до загального ліміту пам'яті.
Із 7 липня Google змінює правила підрахунку використаного сховища для
облікових записів. Відтепер усі дані резервних копій Android
зараховуватимуться до загального ліміту пам'яті. Компанія Motorola оголосила про запуск сервісу Global Connect,
який дозволяє користувачам отримувати доступ до мобільного інтернету
під час закордонних подорожей без необхідності шукати місцевого
оператора або встановлювати нову eSIM в кожній країні.
Компанія Motorola оголосила про запуск сервісу Global Connect,
який дозволяє користувачам отримувати доступ до мобільного інтернету
під час закордонних подорожей без необхідності шукати місцевого
оператора або встановлювати нову eSIM в кожній країні.