Фінансові новини
- |
- 16.07.26
- |
- 21:03
- |
-
 RSS
RSS - |
- мапа сайту
Авторизация
|
| |
|
"Я радше найняв би людину з ентузіазмом, аніж людину, яка все знає" Джон Девісон Рокфеллер |
Вчені у 3200 разів підвищили швидкість читання даних, збережених на ДНК — 10 хвилин замість кількох днів
16:30 25.03.2025 |

Дослідники Ізраїльського технологічного інституту (Technion) розробили метод на основі ШІ, який прискорює пошук даних, збережених у ДНК, на три порядки та одночасно покращує точність.
Молекула ДНК відповідає за збереження генетичного коду живих організмів і складається з послідовності особливих органічних сполук - нуклеотидів. Вони класифікуються за чотирма типами, позначеними літерами A, C, G і T. На відміну від традиційних обчислень, де дані кодуються лише двома цифрами (0 і 1), зберігання у ДНК базується на послідовностях з чотирьох літер, що значно збільшує кількість можливих комбінацій.
Розміщення даних у ДНК може дати справді тривале зберігання інформації (сотні тисяч років) та щільність даних 100 млн разів більшу, ніж наявне цифрове зберігання. Для зберігання даних за цією технологією потрібний синтез ДНК - створення молекул ДНК на основі послідовностей, що кодують інформацію. Щоб прочитати збережені дані, потрібне секвенування ДНК.
Зберігання інформації на ДНК пов'язане з кількома технологічними проблемами. Синтез та секвенування є тривалими процесами, схильними до помилок видалення, вставки та заміни. Через обмеження процесу синтезу створюється кілька копій кожної молекули ДНК, що кодує дані. Ці копії зберігаються разом, без якогось порядку. Під час секвенування трапляються багато помилкових копій цих молекул - більшість з них містять помилки, а деякі повністю зникають.

Нове дослідження, опубліковане в журналі Nature Machine Intelligence, представляє комплексне обчислювальне рішення для пошуку та виправлення помилок у складних системах зберігання на основі ДНК. Використовуючи вдосконалені алгоритми та методи кодування, дослідники продемонстрували, що їх рішення скорочує час пошуку та читання даних з кількох днів до 10 хвилин.
Розроблений у Technion метод DNAformer базується на моделі трансформері, навченій на змодельованих даних, генерованих за допомогою симулятора, який також був розроблений у Technion. Метод реконструює точні послідовності ДНК з помилкових копій. Він включає спеціальний код виправлення помилок, адаптований для ДНК.
Механізм додаткового запасу безпеки виявляє найбільш шумні послідовності ДНК (небажані сигнали або помилки, що виникають під час процесу секвенування, які можуть заважати точній інтерпретації даних) та застосовує алгоритмічні інструменти для ефективнішої обробки. Наприкінці процесу дані переводяться у цифрову інформацію.
Новий метод дозволяє зчитувати 100 МБ даних зі швидкістю, яка у 3200 разів перевищує найточніший наявний метод, без втрати точності. У порівнянні з раніше відомими швидкими методами, DNAformer також покращує точність до 40%. Це було продемонстровано на наборі даних розміром 3,1 МБ, який включав 24-секундний аудіозапис слів астронавта Ніла Армстронга на Місяці, письмовий текст, в якому обговорюються переваги ДНК як перспективного методу зберігання даних, випадкові дані.
Дослідники планують розробити індивідуальні версії DNAformer, адаптовані до різних потреб. Вони підкреслюють, що їхня технологія є масштабованою та адаптованою, тобто її можна оптимізувати для великомасштабних програм зберігання даних, у відповідь на вимоги ринку.
ТЕГИ
 Від закликів до партнерів "Закрийте небо над Україною!" до заяви
українського президента Володимира Зеленського: "Freyja - це спосіб
доповнити нашу оборону, створити надійний щит над усією Європою"
минуло чотири з половиною роки.
Від закликів до партнерів "Закрийте небо над Україною!" до заяви
українського президента Володимира Зеленського: "Freyja - це спосіб
доповнити нашу оборону, створити надійний щит над усією Європою"
минуло чотири з половиною роки. ТОП-НОВИНИ
 Україна першою отримає нові французько-італійські системи SAMP/T NG для протидії балістичним ракетам.
Україна першою отримає нові французько-італійські системи SAMP/T NG для протидії балістичним ракетам.  Верховна Рада проголосувала за звільнення Юлії Свириденко з посади
прем'єр-міністерки України, що означає відставку всього складу Кабінету
міністрів.
Верховна Рада проголосувала за звільнення Юлії Свириденко з посади
прем'єр-міністерки України, що означає відставку всього складу Кабінету
міністрів. Верховна Рада підтримала в першому читанні законопроєкт №15294 про
посилення відповідальності за виготовлення і розповсюдження дитячої
порнографії, що також містить положення про декриміналізацію дорослого
контенту.
Верховна Рада підтримала в першому читанні законопроєкт №15294 про
посилення відповідальності за виготовлення і розповсюдження дитячої
порнографії, що також містить положення про декриміналізацію дорослого
контенту. На Міжурядовій конференції Україна-ЄС офіційно
відкрили Кластер 6 у переговорах про вступ України до ЄС, під назвою
«Зовнішні відносини».
На Міжурядовій конференції Україна-ЄС офіційно
відкрили Кластер 6 у переговорах про вступ України до ЄС, під назвою
«Зовнішні відносини».ПІДПИСКА НА НОВИНИ
ПРЕС-РЕЛІЗИ
 Ця тилова вакансія підходить для кандидатів, що не можуть
виконувати бойові завдання у звʼязку із віком чи станом здоровʼя.
Ця тилова вакансія підходить для кандидатів, що не можуть
виконувати бойові завдання у звʼязку із віком чи станом здоровʼя.  Страхова компанія VUSO (ВУСО) за
підсумками 2025 року сплатила понад 348 мільйонів гривень податків до
бюджетів усіх рівнів. Водночас загальний обсяг допомоги компанії Силам
оборони України з початку повномасштабної війни наближається до 100
мільйонів гривень.
Страхова компанія VUSO (ВУСО) за
підсумками 2025 року сплатила понад 348 мільйонів гривень податків до
бюджетів усіх рівнів. Водночас загальний обсяг допомоги компанії Силам
оборони України з початку повномасштабної війни наближається до 100
мільйонів гривень. У РУБРИЦІ
 Від кінця 2022 року, коли компанія OpenAI публічно представила
ChatGPT - перший масовий чат-бот штучного інтелекту (ШІ), минуло зовсім
небагато часу за мірками людства і ціла вічність для технологій.
Від кінця 2022 року, коли компанія OpenAI публічно представила
ChatGPT - перший масовий чат-бот штучного інтелекту (ШІ), минуло зовсім
небагато часу за мірками людства і ціла вічність для технологій.
 Європейський Союз (ЄС) запровадить вікові обмеження для неповнолітніх
користувачів соціальних мереж. Про це в понеділок, 13 липня, заявила
голова Єврокомісії (ЄК) Урсула фон дер Ляєн
Європейський Союз (ЄС) запровадить вікові обмеження для неповнолітніх
користувачів соціальних мереж. Про це в понеділок, 13 липня, заявила
голова Єврокомісії (ЄК) Урсула фон дер Ляєн  Флагман OPPO Find X10 Pro Max, котрий вийде восени, вперше в історії
смартфонів отримає три камери по 200 МП, повідомляє інсайдер Digital
Chat Station. Ще 50 МП приходиться на фронтальну камеру.
Флагман OPPO Find X10 Pro Max, котрий вийде восени, вперше в історії
смартфонів отримає три камери по 200 МП, повідомляє інсайдер Digital
Chat Station. Ще 50 МП приходиться на фронтальну камеру. Глобальні реєстрації електромобілів і plug-in гібридів у червні зросли на 7% у річному вимірі - до 2 млн одиниць.
Глобальні реєстрації електромобілів і plug-in гібридів у червні зросли на 7% у річному вимірі - до 2 млн одиниць.  Угода про виробництво чипів між Apple та Intel могла бути підписана під
тиском, оскільки адміністрація Білого дому планувала запровадити
100-відсоткові мита на кремній, який використовується в iPhone та Mac.
Угода про виробництво чипів між Apple та Intel могла бути підписана під
тиском, оскільки адміністрація Білого дому планувала запровадити
100-відсоткові мита на кремній, який використовується в iPhone та Mac.  Компанія Radia розширила команду інженерів, що працюють над своїм
вантажним літаком WindRunner, обравши аерокосмічні компанії Latecoere та
Stirling Dynamics для розробки двох найважливіших систем літака.
Компанія Radia розширила команду інженерів, що працюють над своїм
вантажним літаком WindRunner, обравши аерокосмічні компанії Latecoere та
Stirling Dynamics для розробки двох найважливіших систем літака.
 OpenAI офіційно представила ChatGPT Work - новий інструмент, який
об'єднує можливості чат-бота, агента для виконання завдань і
програмування в одному застосунку.
OpenAI офіційно представила ChatGPT Work - новий інструмент, який
об'єднує можливості чат-бота, агента для виконання завдань і
програмування в одному застосунку. BIN™ не завжди поділяє думку авторів публікацій
Любе використання інформації агентств "Українські Новини" та "інтерфакс-Україна" ЗАБОРОНЕНО!
 Google
оголосила про запуск нової функції Video Remix для сервісу Google
Photos. Вона дає змогу редагувати та стилізувати вже збережені відео за
допомогою штучного інтелекту Gemini Omni, який виконує зміни на основі
текстових підказок користувача.
Google
оголосила про запуск нової функції Video Remix для сервісу Google
Photos. Вона дає змогу редагувати та стилізувати вже збережені відео за
допомогою штучного інтелекту Gemini Omni, який виконує зміни на основі
текстових підказок користувача. Samsung оголосила про початок серійного виробництва SSD PM1763 PCIe 6.0, призначеного для серверів наступного покоління.
Samsung оголосила про початок серійного виробництва SSD PM1763 PCIe 6.0, призначеного для серверів наступного покоління. Компанія Meta анонсувала модель штучного інтелекту Muse Image для
генерації та редагування зображень. Це перша розробка підрозділу Meta
Superintelligence Labs у цьому напрямі.
Компанія Meta анонсувала модель штучного інтелекту Muse Image для
генерації та редагування зображень. Це перша розробка підрозділу Meta
Superintelligence Labs у цьому напрямі.  Google
почав використовувати завантажені у пошук фото, аудіо й відео для
навчання своїх ШІ-моделей, і опція увімкнена в усіх за замовчуванням.
Google
почав використовувати завантажені у пошук фото, аудіо й відео для
навчання своїх ШІ-моделей, і опція увімкнена в усіх за замовчуванням.
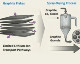 Південнокорейські дослідники розробили нову технологію виробництва
сухих електродів з гранул графіту з контрольованою формою для анодів акумуляторів електрокарів.
Південнокорейські дослідники розробили нову технологію виробництва
сухих електродів з гранул графіту з контрольованою формою для анодів акумуляторів електрокарів. Із 7 липня Google змінює правила підрахунку використаного сховища для
облікових записів. Відтепер усі дані резервних копій Android
зараховуватимуться до загального ліміту пам'яті.
Із 7 липня Google змінює правила підрахунку використаного сховища для
облікових записів. Відтепер усі дані резервних копій Android
зараховуватимуться до загального ліміту пам'яті. Компанія Motorola оголосила про запуск сервісу Global Connect,
який дозволяє користувачам отримувати доступ до мобільного інтернету
під час закордонних подорожей без необхідності шукати місцевого
оператора або встановлювати нову eSIM в кожній країні.
Компанія Motorola оголосила про запуск сервісу Global Connect,
який дозволяє користувачам отримувати доступ до мобільного інтернету
під час закордонних подорожей без необхідності шукати місцевого
оператора або встановлювати нову eSIM в кожній країні.